

💡Abstract
Visual reasoning over structured data such as tables is a critical capability for modern vision-language models (VLMs), yet current benchmarks remain limited in scale, diversity, or reasoning depth, especially when it comes to rendered table images.
Addressing this gap, we introduce Visual-TableQA, a large-scale, open-domain multimodal dataset specifically designed to evaluate and enhance visual reasoning over complex tabular data. Our generation pipeline is modular, scalable, and fully autonomous, involving multiple reasoning LLMs collaborating across distinct roles: generation, validation, and inspiration.
Visual-TableQA comprises 2.5k richly structured LaTeX-rendered tables and 9k reasoning-intensive QA pairs, all produced at a cost of under $100. To promote diversity and creativity, our pipeline performs multi-model collaborative data generation via cross-model prompting (‘inspiration’) and LLM-jury filtering. Stronger models seed layouts and topics that weaker models elaborate, collectively distilling diverse reasoning patterns and visual structures into the dataset.
Empirical results show that models fine-tuned on Visual-TableQA generalize robustly to external benchmarks, outperforming several proprietary models despite the dataset’s synthetic nature.
Pipeline
The full pipeline and resources are publicly available in our GitHub repository.
📊 Results
Below is a sample of tables and QA pairs generated through our pipeline:
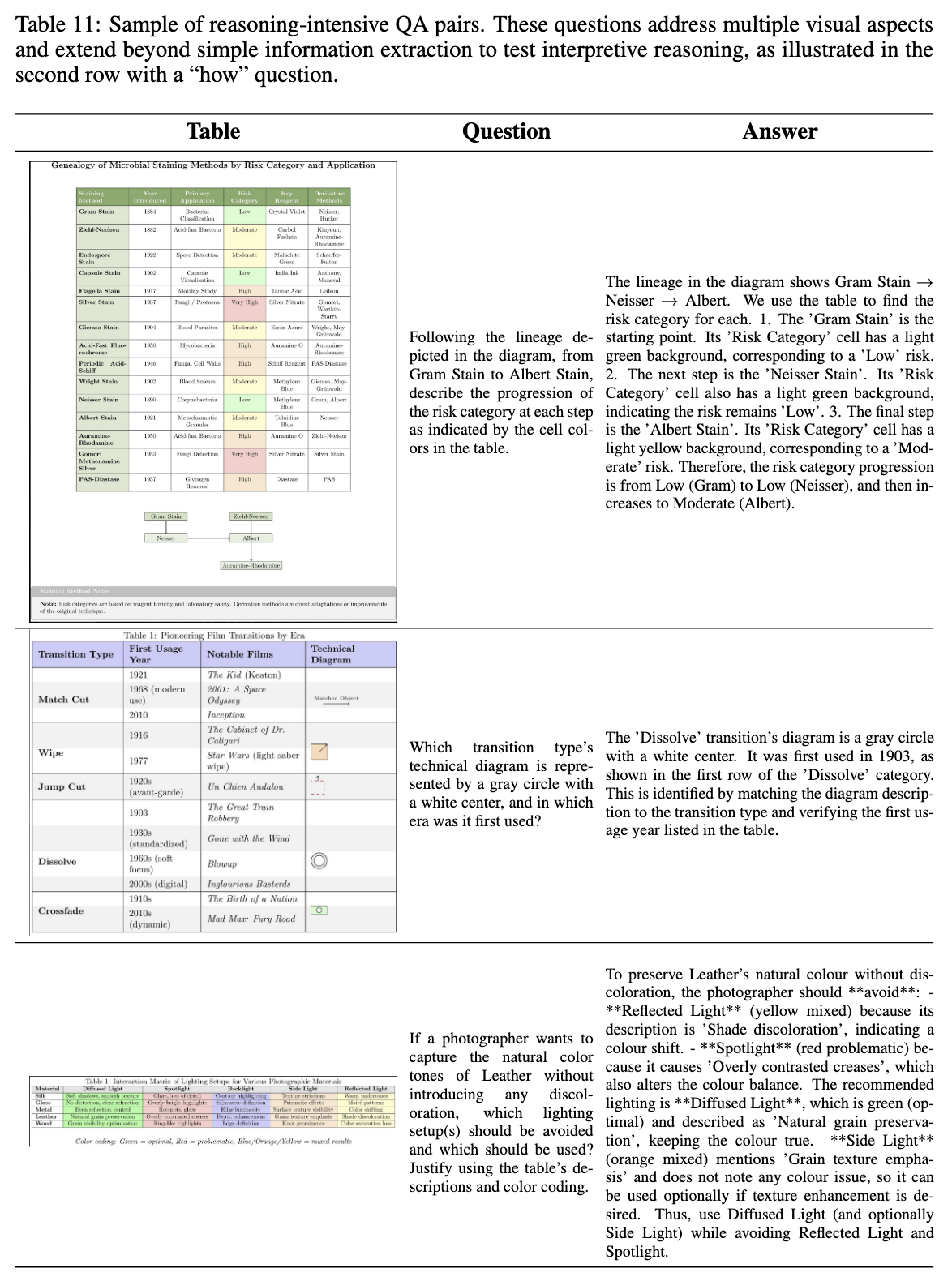
The full dataset is available on Hugging Face.
We also report the LLM jury agreement over dataset quality in the figure below:
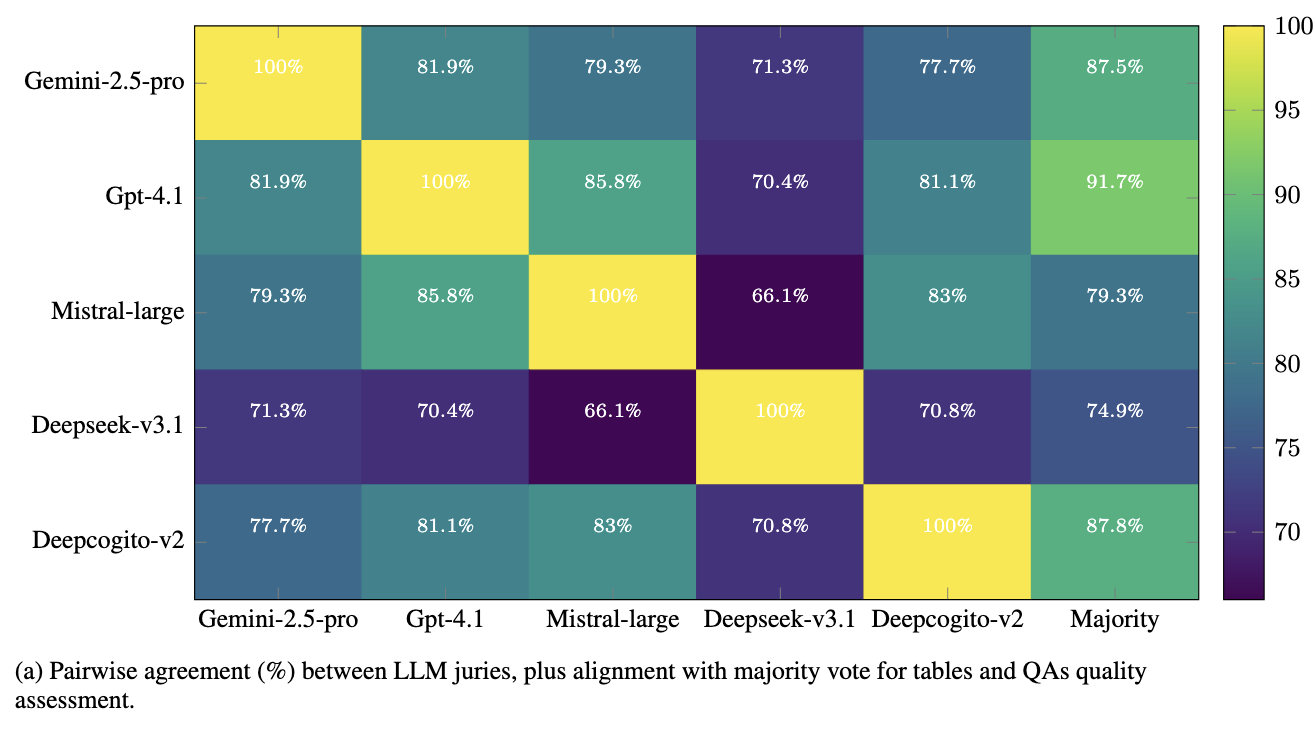
The analysis shows varying levels of consistency across juries. GPT-4.1 stands out as the most reliable, likely due to its ability to handle edge cases effectively. Proprietary models such as Gemini-2.5-pro and GPT-4.1 align most closely with the majority vote, while Deepseek-v3.1 demonstrates the weakest agreement. Interestingly, the pairwise jury agreement patterns seem correlated with the models’ reasoning strength. Despite differences in alignment, all juries maintain a meaningful level of concordance with the majority, underscoring the robustness of our evaluation protocol.
🚀 Application
A natural next step for this dataset is to fine-tune VLMs to strengthen their reasoning abilities.
This direction is explored in a follow-up project, which you can find here.
📚 Citation
If you use this code or dataset in your research, please cite:
BibTeX:
@inproceedings{
lompo2025visualtableqa,
title={Visual-Table{QA}: Open-Domain Benchmark for Reasoning over Table Images},
author={Boammani Aser Lompo and Marc Haraoui},
booktitle={NeurIPS 2025 Workshop on Foundations of Reasoning in Language Models},
year={2025},
url={https://openreview.net/forum?id=fvJRsGwhPf}
}