

A VLM easily solves a textual task, then a mirror converts the task into a visual format that the same model finds harder.
💡Abstract
Inspired by previous works (He et al., 2025), we introduce modality swap, a training strategy in which language models use their textual reasoning and coding capabilities to generate synthetic LaTeX tables that are rendered into images and then used for visual reasoning training. This setup allows smaller VLMs to contribute to their own improvement by transferring competence from text (structured generation and code) to vision (reasoning over rendered tables).
We instantiate this idea with Visual-TableQA, built through a modular, scalable, and fully autonomous pipeline. Multiple LLMs coordinate across roles—generation, validation, and inspiration (cross-model prompting)—to produce 2.5k richly structured LaTeX-rendered tables and 9k reasoning-intensive QA pairs at a cost under $100. The pipeline includes LLM-jury filtering and cross-model inspiration, where stronger models propose structural seeds and topics that other models elaborate.
In experiments, models fine-tuned on Visual-TableQA show robust generalization to external benchmarks; in some settings, results are competitive with or exceed proprietary baselines. An ablation also indicates higher scores when queries are presented in textual rather than visual form, consistent with the intended cross-modal transfer from text to vision.
📊 Results
The complete dataset can be accessed on Hugging Face.
The figures below report the outcomes of supervised finetuning on Visual-TableQA:
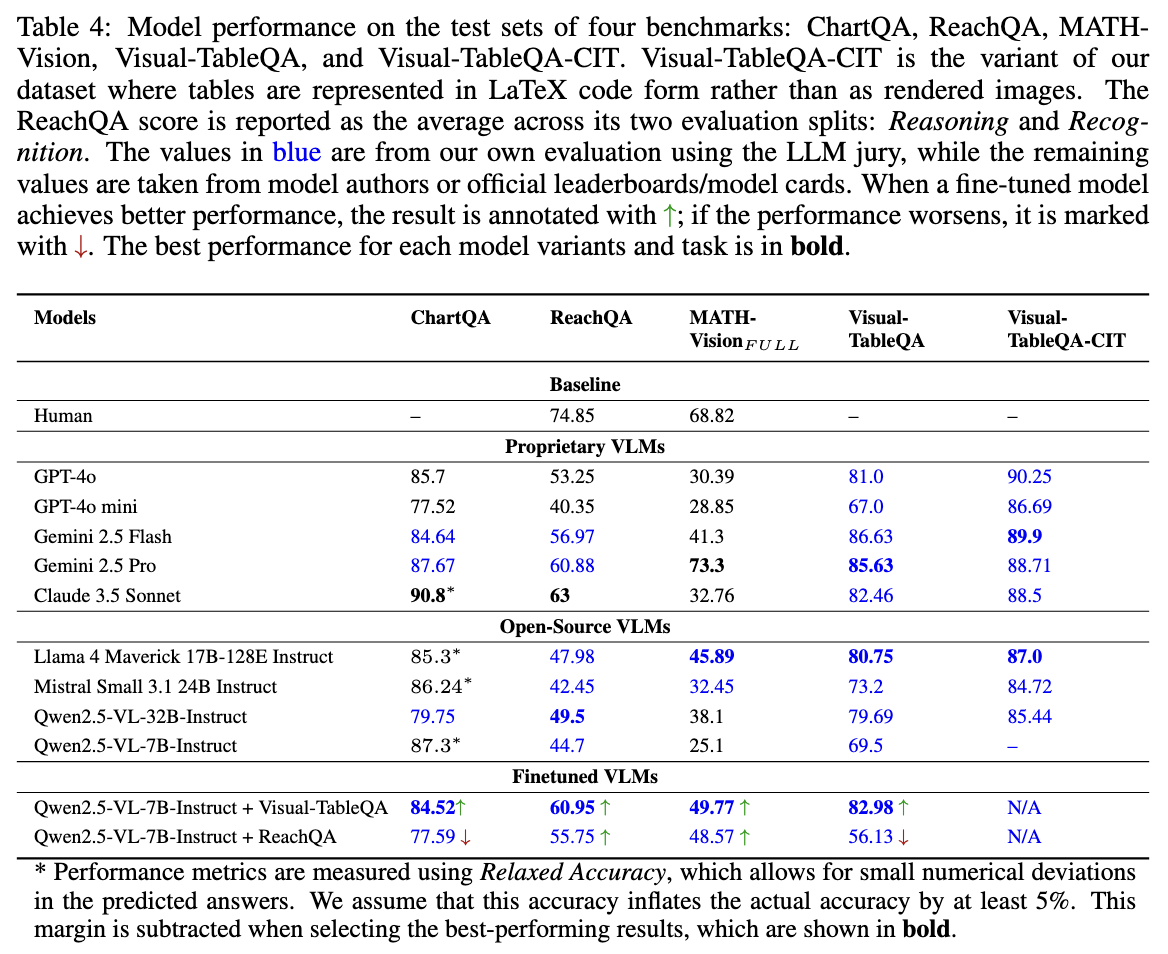
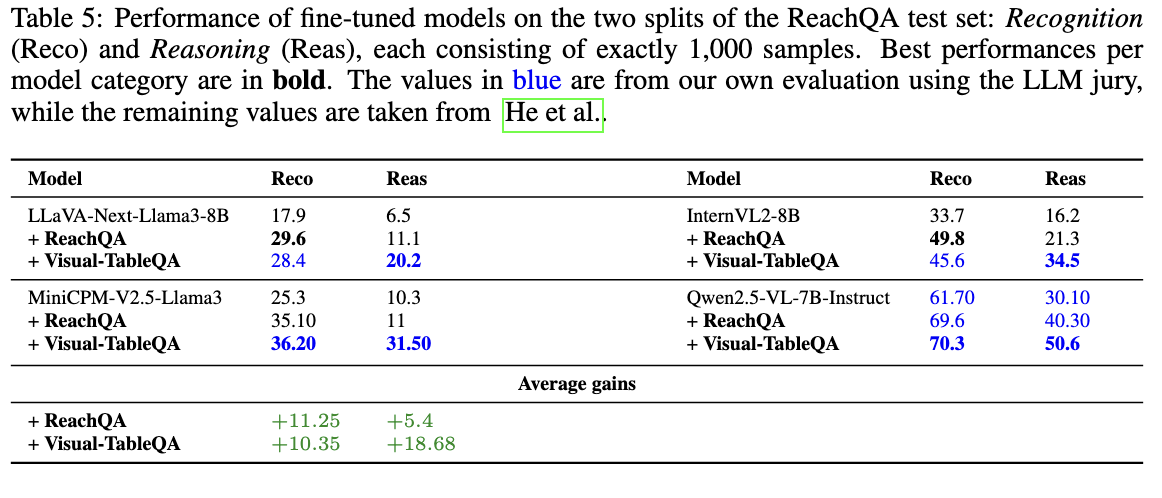
The results highlight that supervision from Visual-TableQA enables models to generalize well beyond the dataset’s native domain, while also challenging models finetuned on other benchmarks. This demonstrates both the value of reasoning-rich data and the higher level of complexity offered by our dataset compared to alternatives.
We also report the LLM jury agreement over dataset quality in the figure below:
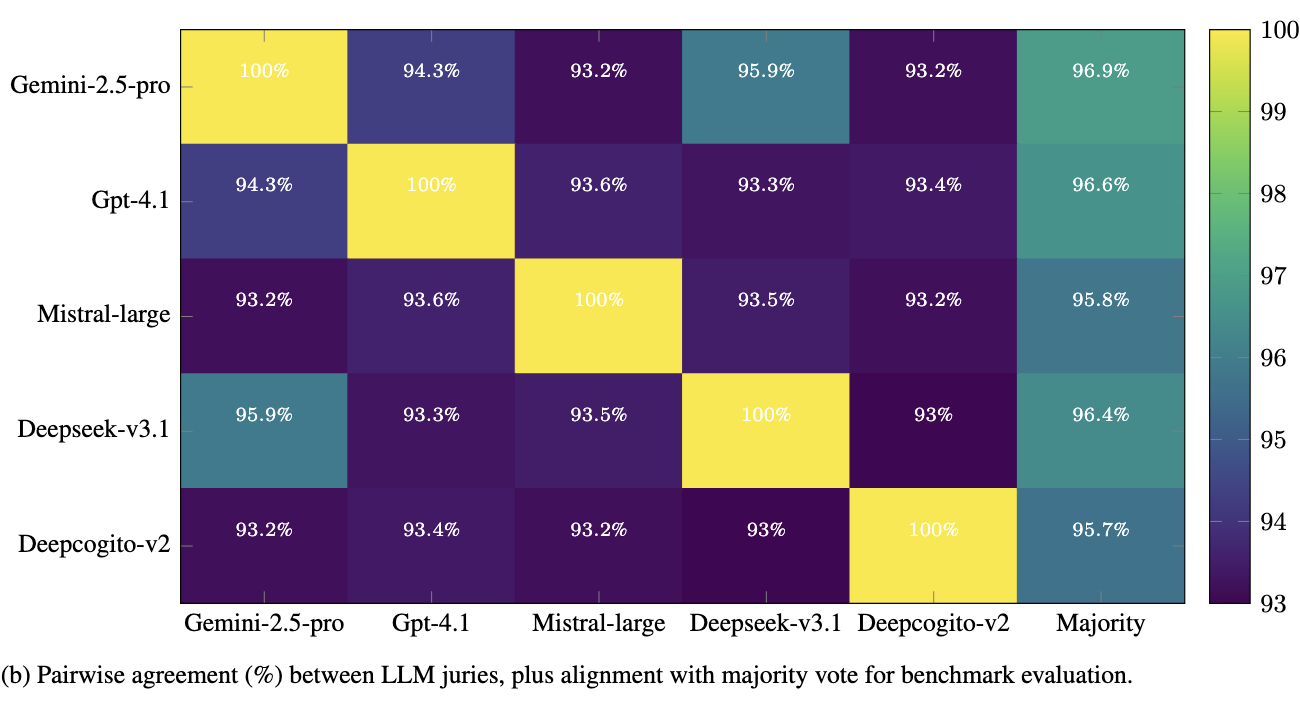
This Table shows consistently strong jury agreement across all models for benchmark evaluations, with no notable divergence between proprietary and open-source LLMs. This can be attributed to the relatively simpler nature of the task (semantic comparison between model predictions and ground truth).
📚 Citation
Will be released upon acceptance.